Følger, rekker og lån
Følger og rekker
En tallfølge er en ordnet liste med tall:
En rekke er summen av tallene i en tallfølge. Delsummen
Tabell: Formler til følger og rekker
| Forklaring | Formel |
|---|---|
| Ledd i aritmetisk følge (rekursiv) | |
| Ledd i aritmetisk følge (eksplisitt) | |
| Ledd i geometrisk følge (rekursiv) | |
| Ledd i geometrisk følge (eksplisitt) | |
| Aritmetisk rekke (sum av følge) | |
| Geometrisk rekke (sum av følge) | |
| Uendelig geometrisk rekke |
Rekker og konvergens
En rekke konvergerer og har summen
En enkel tommelfingerregel for å sjekke om en rekke konvergerer er å sjekke om leddene går mot 0 når
Uendelige geometriske rekker
Geometriske rekker er alltid konvergente når kvotienten
En uendelig geometrisk rekke kan ha en kvotient
Summen av slike rekker er gitt ved en funksjon
Programmering av følger og rekker
Ifølge læreplanen skal dere utforske rekursive sammenhenger med programmering. En rekursiv sammenheng vil si at vi bruker ett ledd til å regne ut det neste leddet – for å regne ut
Ledd i aritmetisk tallfølge
# Regner ut de første leddene i en aritmetisk tallfølge med a_1 = 0 og d = 2.
a = 0
d = 2
n = 10
for i in range(1, n + 1):
print(f"a_{i} = {a}")
a = a + d
Ved bruk av print(f"") så kan vi blande tekst og variabler. Du henter ut verdien av variablene ved å skrive krøllparenteser slik: {variabelnavn}.
Delsum av geometrisk rekke
# Regner ut de første leddene og delsummene i geometrisk rekke med a_1 = 1 og k = 1.5
a = 1
k = 1.5
delsum = a
n = 10
for i in range(1, n + 1):
print(f"a_{i} = {a:.2f}. s_{i} = {delsum:.2f}")
a = a * k
delsum = delsum + a
Her bruker vi en teller, delsum, som i hver omgang av for-løkka blir oppdatert med den nye summen.
Vi kan avrunde desimaltall med {variabelnavn:.2f} der 2-tallet er antallet desimaler vi ønsker.
Eksempel med følge som ikke er geometrisk eller aritmetisk
Oppgavetekst: Gitt følgende tallfølge:
De 3 første leddene i denne følgen er spesielle. Deretter følger tallene et fast mønster.
Lag et program som skriver ut de første n leddene i denne følgen. Hvis programmet ditt fungerer riktig vil du få
.
Etter å ha funnet ut at
Vi kan programmere dette på følgende måte
a_minus3 = 1
a_minus2 = 3
a_minus1 = 4
n = 50
for i in range(4, n + 1):
a = a_minus3 + a_minus2 + a_minus1
print(f"a_{i} = {a}")
a_minus3 = a_minus2
a_minus2 = a_minus1
a_minus1 = a
Her oppdaterer vi hele tiden verdiene av de tre foregående leddene.
Vi kan også løse den samme oppgaven ved bruk av lister. Her bruker vi metoden append på lista a. Dette legger til et nytt element i slutten av lista. Dette nye elementet skal være lik summen av de tre foregående leddene.[1]
a = [1, 3, 4]
antall_ledd = 50
for i in range(4, antall_ledd+1):
a.append(a[i-2] + a[i-3] + a[i-4])
print(a)
Nåverdi og lån
Tabell: Ordliste med begreper knyttet til lån og nåverdi
| Begrep | Forklaring |
|---|---|
| Rentefot/-sats | Hvor mange prosent rente vi må betale per år |
| Terminer | Antall innbetalinger |
| Lånebeløp | Størrelsen på lånet da du tok det opp |
| Restlån | Størrelsen på lånet i dag |
| Terminbeløp | Hvor mye penger du betaler i hver termin |
| Renter | Den delen av terminbeløpet som dekker rentene |
| Avdrag | Den delen av terminbeløpet som betaler ned på lånet |
| Termingebyr | Bankens gebyr for å sende ut faktura |
Nåverdi
Nåverdi forteller oss hvor mye et fremtidig (eller fortidig) beløp er verdt i nåtidens penger. Det er vanlig at penger blir mindre og mindre verdt for hvert år siden vi forventer avkastning på investeringene våre.
Nåverdien
Der
Serielån
I et serielån er alle avdragene like store, men rentene minker og derfor minker også terminbeløpene.
Vi finner avdragene med
Vi finner terminbeløpene med
Terminbeløpene danner en aritmetisk rekke hvor terminbeløp nummer
Annuitetslån
I et annuitetslån er alle terminbeløpene like store. Rentene synker i løpet av nedbetalingsperioden og avdragene øker. Lånebeløpet
Der
Legg merke til at dette er en geometrisk rekke med
Formler for annuitetslån
Jeg anbefaler heller å lære seg å sette opp rekker i CAS eller å sette opp annuitetslån i Excel. Formlene i dette delkapittelet vil fungere, men de vil ikke hjelpe deg til å forstå rekker.
Vi kan også bruke formler til å regne ut terminbeløpene eller lånebeløpet til et annuitetslån. Lånebeløpet
Vi finner terminfaktoren ved hjelp av følgende formel hvor
Målsøking i Excel
Målsøking er et verktøy i Excel som brukes når du vet hvilket resultat du ønsker, men ikke hvilken inngangsverdi som gir dette resultatet. Excel endrer automatisk på inngangsverdien og prøver seg fram helt til regnearket gir riktig svar.
Eksempel med serielån
La oss se på et eksempel hvor vi tar opp et serielån på 50 000 kr som skal betales ned over 5 år med én innbetaling hvert år. Vi kan sette opp en oversikt over nedbetalingene i Excel slik som figuren under viser.

Legg merke til at vi bruker formler i så mange av cellene i tabellen som mulig. Det gjør at regnearket blir dynamisk, og at det kan brukes på nytt dersom vi endrer på for eksempel lånebeløpet eller rentefoten.
Finn hva rentefoten måtte ha vært for hvis de samlede renteutgiftene var 5 500 kr.
- Trykk i cellen
E12siden det er denne cellen vi ønsker at skal inneholde målverdien vår, altså. - Åpne verktøyet målsøking ved å søke i søkefeltet på toppen eller ved å navigere til
Data→Hva-skjer-hvis-analyse→Målsøking. - Målsøkingsverktøyet trenger 3 parametere. Vi ønsker at celle
E12skal få verdien 5500. Derfor skriver viE12og5500i de to øverste boksene. Se figur &fig:maalsok. I den nederste boksen skriver du cellen som du skal endre på for å finne målverdien. Du kan også trykke direkte på celle C3. Det er ikke nødvendig med$-tegn her, men det er heller ikke noe farlig med dem.

Vi kan se i celle E12 at rentefoten måtte ha vært
Funksjonsdrøfting
Funksjonsdrøfting handler om å finne ut hvordan funksjoner ser ut når du tegner dem.
- Nullpunkter finner du ved å sette
- Topp-, bunn- og terrassepunkter finner du ved å sette
- Vendepunkter finner du ved å sette
- Monotoniegenskaper (når funksjonen vokser og synker) finner du ved å sjekke når
og . Du trenger å faktorisere og tegne fortegnslinje for å finne ut av dette. - Krumning finner du ved å sjekke når
og . Du trenger å faktorisere og tegne fortegnslinje for å finne ut av dette.
Husk også disse viktige sammenhengene
- Stigningstallet til tangenten i punktet
er lik den deriverte i punktet . - En funksjon har sin maksimalverdi i toppunktene eller randpunktene
- Mange funksjoner har størst vekstfart i vendepunktene.
Logaritmer
Egenskaper ved logaritmefunksjoner
En logaritmefunksjon er den inverse funksjonen til en eksponentialfunksjon.
- Eksponentialfunksjonen
har tilhørende logaritmefunksjon eller ofte bare kalt . - Eksponentialfunksjonen
har tilhørende logaritmefunksjon - Eksponentialfunksjonen
har tilhørende logaritmefunksjon for . Du kan altså velge hvilket som helst positivt tall som base i logaritmefunksjonen.
Siden logaritmefunksjonen og eksponentialfunksjonene er inverse så vil disse nulle hverandre ut:
Logaritmefunksjonene er definert for alle positive tall slik at definisjonsmengden blir
Vi velger som oftest den naturlige logaritmen,
Regneregler for logaritmer
Her bruker jeg den naturlige logaritmen som eksempel, men disse reglene gjelder for alle typer logaritmer.
Tabell: Regneregler for logaritmer
| Forklaring | Formel |
|---|---|
| Bruke logaritme på likning | |
| Hente ned eksponent | |
| Logaritme til produkt | |
| Logaritme til kvotient | |
| Nullpunkt til logaritmer |
Merk at den siste regelen forteller oss at alle typer logaritmefunksjonene har sitt eneste nullpunkt i
Rasjonale funksjoner
En rasjonal funksjon består av en brøk med polynomfunksjoner i teller og nevner:
Rasjonale funksjoner har følgende egenskaper:
- Nullpunkt når telleren
- Bruddpunkt når nevneren
- Definisjonsmengden er alle
bortsett fra bruddpunktet:
Asymptoter
Asymptoter er tenkte linjer som en funksjon nærmer seg. Asymptoter kan være horisontale, vertikale eller skrå.
- Vi får vertikale asymptoter i bruddpunktene. Vi finner disse ved å løse
. - Vi får en horisontal asymptote dersom
og har samme grad. Vi finner den horisontale asymptoten ved å sammenligne leddene i og med høyest grad, og dividere koeffisientene foran disse leddene på hverandre. For eksempel gir funksjonen asymptoten . - Dersom graden til
er større enn graden til får vi en horisontal asymptote i . - Vi får skrå asymptoter når graden av
er én større enn graden av . Vi finner denne ved å beregne med polynomdivisjon. Den skrå asymptoten er svaret på divisjonen når du ser bort fra resten.
Derivasjon
Definisjon: Hvis
Den deriverte i et punkt er lik den momentane vekstfarten i punktet og dermed også lik stigningstallet til tangenten til
Derivasjonsregler
Tabell: Formler for derivasjon
| Forklaring | Funksjon | Derivert |
|---|---|---|
| Konstant | ||
| Potensfunksjon | ||
| Konstante koeff. | ||
| Summer | ||
| Produkt | ||
| Kvotienter | ||
| Eksponentialfunk | ||
| Eksponentialfunk | ||
| Logaritme | ||
| Kjerneregelen | ||
| --- ` | ` --- (Leibniz') | |
| --- ` | ` --- (Leibniz') |
Huskeregel kjerneregelen: Multipliser den deriverte av den ytre funksjonen med den deriverte av kjernen.
Den deriverte av ln x
Merk at selv om
Funksjonen
Stigningstall og tangenter
Stigningstallet,
Vi kan også bruke ettpunktsformelen hvor
Kontinuitet
Tommelfingerregelen er at funksjoner som kan tegnes uten å løfte blyanten er kontinuerlige, men funksjoner kan være kontinuerlige selv om du må løfte blyanten.
En funksjon
Det finnes tre krav for at en funksjon
- Funksjonen eksisterer i punktet, altså
eksisterer - Grenseverdien
må eksistere, altså må både venstre- og høyregrenseverdien være like. - Funksjonsverdien og grenseverdien må være like
Integrasjon
Ubestemte integraler
Et ubestemt integral er å finne alle antideriverte
Tabell: Formler for integrasjon
| Forklaring | Funksjon | Integrert |
|---|---|---|
| Konstant | ||
| Koeffisient | ||
| Flere ledd | ||
| Potensfunksjon | ||
| Spesialtilfelle | ||
| Eksponentialfunksjon | ||
| Naturlig logaritme | ||
| Eksponentialfunksjon[2] |
Bestemt integral som grense av sum
Vi har en funksjon
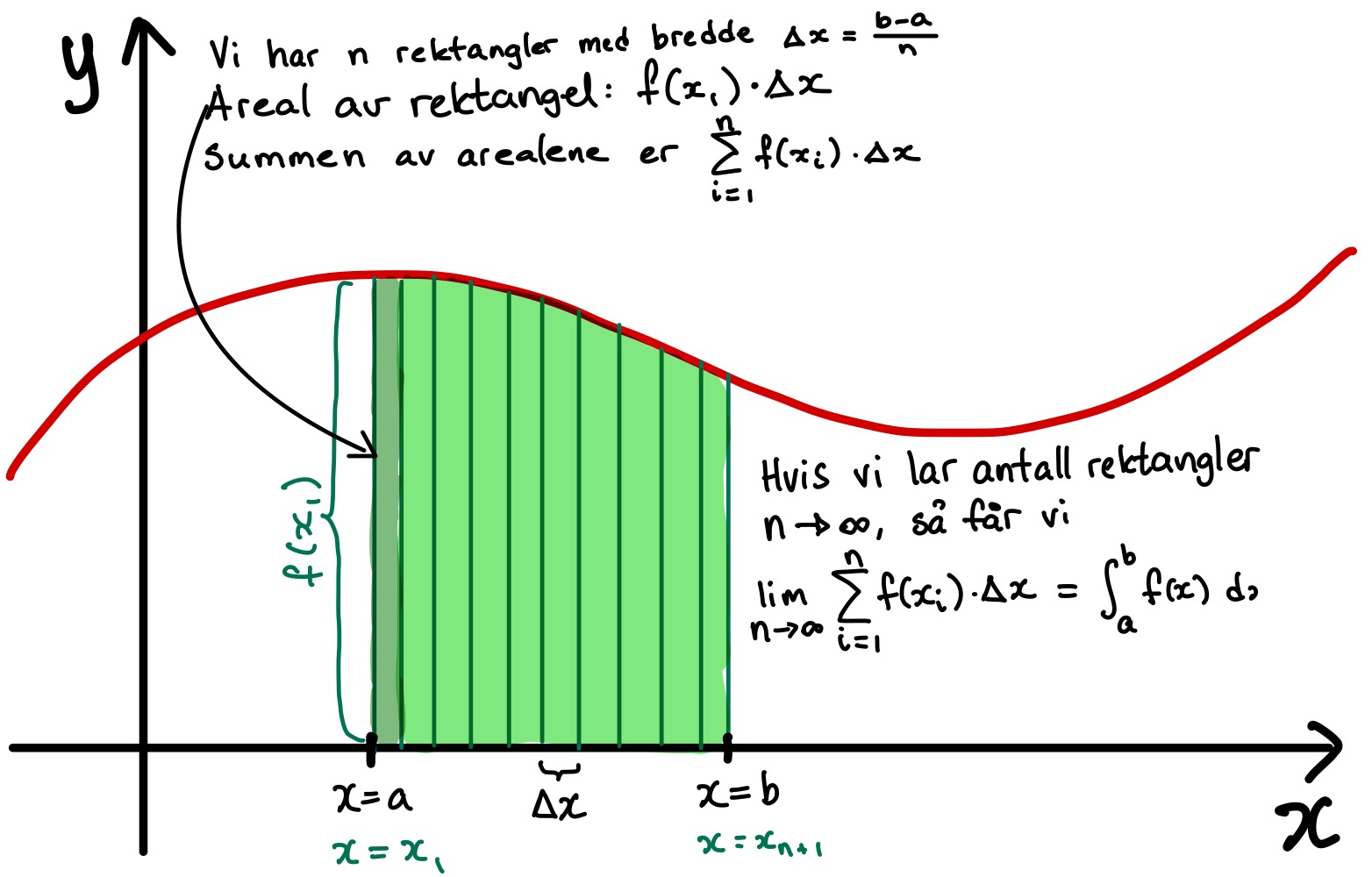
Vi forsøker å dele opp området under grafen i
Hvis vi kaller
Siden arealet til et rektangel er høyde multiplisert med bredde vil summen av arealene til rektanglene altså være
Hvis vi lar bredden av rektanglene bli veldig små slik at rektanglene egentlig bare blir infinitesimalt smale striper får vi
Fundamentalsetningen
Fundamentalsetningen eller analysens fundamentalteorem forteller oss at integrasjon og derivasjon er motsatte operasjoner.
La
Denne første delen av fundamentalsetningen forteller oss at alle kontinuerlige funksjoner
Gitt
Denne andre delen av fundamentalsetningen forteller oss at vi kan beregne et bestemt integral ved hjelp av det ubestemte integralet
Areal under grafer
La
Dersom grafen ligger under
Dersom funksjonen krysser
Areal mellom grafer
Hovedprinsippet for å finne arealet mellom grafer er å ta integralet av den øverste grafen og trekke fra integralet fra den nederste grafen.
La
Areal mellom grafer med to skjæringspunkter
Dersom du får to løsninger
Dersom
Areal mellom grafer med tre eller flere skjæringspunkter
Hvis du har tre eller flere skjæringspunkter mellom
Integrasjonsteknikker
Delvis integrasjon
Delvis integrasjon brukes ofte dersom du skal integrere et produkt av ulike to ulike funksjoner. Du kan gjerne tenke på delvis integrasjon som en omvendt produktregel for derivasjon.
Delvis integrasjon er spesielt nyttig dersom den ene faktoren er enkel å integrere og den andre faktoren er enkel å derivere.
Sett den ene faktoren til å være
DI-metoden for delvis integrasjon
Det er også mulig å bruke oppsettet kalt DI-metoden. Eksempelet under viser DI-metoden for
- Den første kolonnen viser fortegnet. Dette veksler mellom
og . - Den andre kolonnen inneholder faktoren som skal deriveres (D). For hver rad så deriverer du faktoren.
- Den tredje kolonnen inneholder faktoren som skal integreres (I). For hver rad så integrerer du faktoren.
| D | I | |
|---|---|---|
Svaret med DI-metoden finner du ved å starte på fortegnet oppe til venstre (
Du lager rader i tabellen fram til du får en null, eller helt til du ser at du kan integrere produktet av faktorene i en rad. Hvis du ser at du kan integrere produktet av faktorene i en rad (for eksempel kan vi integrere produktet av 2 og
Når du løser dette vil du få samme svar som tidligere.
Variabelskifte
Variabelskifte brukes hvis du skal integrere en sammensatt funksjon. Variabelskifte kalles ofte for den omvendte kjerneregelen.
- Velg en del av integranden som
, dette er variabelskiftet ditt. - Deriver
slik at du finner . - Løs likningen med hensyn på
slik at du får - Substituer
med i det opprinnelige uttrykket ditt. - Substituer inn
i integranden. - Integrer uttrykket som nå har formen
- Substituer ut alle
i svaret med det opprinnelige uttrykket for
Dersom du kan derivere en av faktorene i integranden, og den deriverte blir lik en annen faktor i integranden så bør du bruke variabelskifte. Ta for deg følgende regnestykke
Vi vet at
Vi setter
Vi kan nå bytte ut
Vi bytter tilbake
Delbrøkoppspalting
Jeg vet ikke om det er nødvendig å kunne delbrøkoppspalting til del 1 av eksamen. Hvis du sikter mot karakteren 6 så ville jeg definitivt lært den. Hvis du sikter mot 4 eller lavere så ville jeg definitivt prioritert andre deler av pensum.
Delbrøkoppspalting er en teknikk som vi blant annet kan bruke til å løse integraler med rasjonale uttrykk (se kapittel 2.2). Teknikken går ut på å skrive om en komplisert rasjonal funksjon til en sum av flere enkle rasjonale funksjoner. La
For at vi skal kunne gjøre delbrøkoppspalting må
- Sjekk at nevner har høyere grad enn teller, ellers må du gjennomføre polynomdivisjon først
- Faktoriser uttrykket i nevneren til
faktorer - Sett uttrykket lik summen av
brøker: over faktor 1, over faktor 2 og så videre opp til - Multipliser begge sider av likningen med fellesnevner
- Sett inn
-verdier som du ser at vil hjelpe deg med å bestemme , og så videre - Skriv om det opprinnelige uttrykket som summen av
brøker - Integrer ledd for ledd
Jeg viser en delbrøkoppspalting med eksempelet
Vi ser at vi har tre faktorer i nevneren. Vi går videre til punkt 3 og setter uttrykket vårt lik summen av tre brøker:
Vi går videre til punkt 4 og multipliserer med fellesnevneren
Vi går videre til punkt 5 og ser at hvis vi setter inn
Vi har altså bestemt
Vi kan dermed gå videre til punkt 7 og faktisk integrere uttrykket ledd for ledd
Økonomi
Her lar vi
Grenseinntekt og grensekostnad
Grenseinntekten
Grensekostnaden
Vi bruker også begrepene marginalinntekt og marginalkostnad.
Maksimalt overskudd
Vi har maksimalt overskudd når grenseinntekt er lik grensekostnad fordi
Hvis du får flere løsninger så bør du sjekke hvilke løsninger som er toppunkter.
Enhetskostnader
Enhetskostnaden
Vi kan finne de laveste enhetskostnadene på tre måter:
- Ved å løse likningen
- Ved å finne en tangent til kostnadsfunksjonen som går gjennom origo
- Ved å løse
. Utledningen for den siste formelen er som følger
Vi setter uttrykket til den deriverte
Etterspørsel
Etterspørselen
Inntektene er
På samme måte kan vi vise at kostnadene blir
Sannsynlighet og statistikk
Diskrete sannsynlighetsfordelinger
I diskrete sannsynlighetsfordelinger så inneholder utfallsrommet til den stokastiske variabelen
Dersom du kaster to mynter og lar
Uniform sannsynlighetsfordeling
I en uniform sannsynlighetsfordeling er sannsynligheten for alle utfallene like stor. Et eksempel på uniform sannsynlighetsfordeling er et terningkast: her har alle de seks sidene like stor sannsynlighet.
For å regne ut sannsynlighet ved uniform sannsynlighet tar vi
Binomisk sannsynlighetsfordeling
Vi bruker binomiske fordelinger når vi kun har to ulike utfall. Vi bruker ofte binomisk fordeling når vi definerer at en hendelse enten inntreffer eller så inntreffer den ikke.
Hvis vi gjør det samme binomiske forsøket flere ganger etter hverandre får vi en binomisk sannsynlighetsfordeling. Vi kaller antall forsøk for
La
- Alle delforsøkene må være uavhengige
- Sannsynligheten for suksess,
, er lik i alle delforsøkene
Hypergeometrisk sannsynlighetsfordeling
Vi bruker hypergeometrisk sannsynlighetsfordeling når vi har to ulike grupper med gjenstander og skal få et gitt antall av hver av dem. I hypergeometriske forsøk så er ikke delforsøkene uavhengige av hverandre.
Du har to typer objekter i en bolle, hvorav
Forventningsverdi, varians og standardavvik
Forventningsverdi
Forventningsverdi er den gjennomsnittlige verdien vi kan forvente over lang tid. Forventningsverdien til
Vi bruker vanligvis en tabell med sannsynlighetsfordelingen for å regne ut forventingsverdien. Nedenfor er et eksempel som viser sannsynlighetsfordelingen når
| 0 | ||
| 1 | ||
| Sum | 1 |
Forventningsverdi i binomisk sannsynlighetsfordeling
I binomisk sannsynlighetsfordeling hvor antall forsøk er
Forventningsverdi i kontinuerlige sannsynlighetsfordelinger
I kontinuerlige sannsynlighetsfordelinger finner vi forventningsverdien til
hvor
Varians og standardavvik
Varians og standardavvik er spredningsmål – de måler variasjonen i observasjonene våre.
- Standardavviket er kvadratroten av variansen:
- Standardavvik har samme måleenhet som observasjonene våre
- Variansen har måleenheten til observasjonene opphøyd i andre
Variansen til
Hvis vi ikke allerede har fått oppgitt forventningsverdien bruker vi vanligvis en tabell med sannsynlighetsfordelingen for å regne ut variansen. Nedenfor er et eksempel som viser sannsynlighetsfordelingen når
| Sum | 1 |
Fra summen i den femte kolonnen ser vi at
Varians i binomisk fordeling
I binomisk sannsynlighetsfordeling hvor antall forsøk er
Varians i kontinuerlige sannsynlighetsfordelinger
I kontinuerlige sannsynlighetsfordelinger finner vi variansen til
hvor
Regneregler for forventningsverdi og varians
La
Regneregler for sum av stokastiske variabler
La
Hvis (og bare hvis)
Kontinuerlige sannsynlighetsfordelinger
I kontinuerlige sannsynlighetsfordelinger så inneholder utfallsrommet til den stokastiske variabelen
Sannsynligheten for at
Her er
Legg merke til at
Punktsannsynligheter i kontinuerlige sannsynlighetsfordelinger er lik null (altså
må ha en definisjonsmengde
Normalfordelingen
Normalfordelingen er en kontinuerlig sannsynlighetsfordeling med tetthetsfunksjon gitt ved
Definisjonsmengden er
Standard normalfordeling
Alle normalfordelinger kan gjøres om til en standard normalfordeling med forventningsverdi
La
Deretter bestemmer vi sannsynligheten
Normalfordeling som tilnærming for binomiske fordelinger
Binomiske fordelinger blir tilnærmet normalfordelte når antall forsøk
Forventningsverdi og varians er den samme for begge fordelingene.
La
Siden
Sentralgrensesetningen
Sentralgrensesetningen sier at dersom vi gjør tilstrekkelig mange forsøk, vil gjennomsnittet til alle stokastiske variabler være tilnærmet normalfordelt hvis
- De stokastiske variablene er uavhengige
- De stokastiske variablene har samme sannsynlighetsfordeling
La
Vi lar
Når
Denne tilnærmingen er best for store verdier av
Simuleringer med Python
Vi bruker ofte Monte Carlo[3]-simuleringer i programmer for å finne sannsynligheter som er vanskelig å bestemme ved regning. Prinsippet for slike simuleringer er:
- Du definerer en hendelse
- Du gjennomfører et stokastisk forsøk
ganger - Du teller antall ganger
inntreffer og kaller denne summen for - Du beregner sannsynligheten ved:
Dette er imidlertid ikke den ekte sannsynligheten, men
Å trekke fra en sannsynlighetsfordeling
Vi kan trekke ut en tilfeldig prøve fra mange ulike statistiske fordelinger. I S2 skal vi fokusere på:
- Uniform sannsynlighetsfordeling: alle utfallene er like sannsynlige
- Binomisk sannsynlighetsfordeling
- Hypergeometrisk sannsynlighetsfordeling
- Normalfordeling
Vi bruker funksjoner fra biblioteket random og numpy.random til å gjøre uttrekk. Vi må derfor ha med en importeringslinje som import random i toppen av programmene våre.
Trekke tilfeldig heltall
For å trekke et tilfeldig heltall i intervallet random.randint(a,b).
import random
tilfeldig_tall = random.randint(1,6)
Trekke tilfeldig desimaltall
For å trekke et tilfeldig desimaltall i intervallet random.random(). Hvis du trenger å ha et tilfeldig desimaltall i intervallet
import random
tilfeldig_tall = random.random()
tilfeldig_tall2 = 10 * random.random() + 5
Trekke fra normalfordeling
For å trekke et tilfeldig tall fra en normalfordeling med forventningsverdi random.gauss(mu, sigma).
import random
tilfeldig_tall = random.gauss(180, 7)
Trekke fra hypergeometrisk fordeling
For å trekke et tilfeldig tall fra en hypergeometrisk fordeling må vi bruke numpy.random.hypergeometric(n_1, n_2, k). Vi importerer biblioteket med import numpy as np også bruker vi funksjonen som vist under med np.random.hypergeometric().
I eksempelet under så har vi 20 fotballspillere (
import numpy as np
tilfeldig_tall = np.random.hypergeometric(20, 30, 3)
Trekke fra binomisk fordeling
Vi bruker numpy.random.binomial(n, p) for å trekke fra en binomisk fordeling med antall
For å simulere antallet frø som spirer hvis vi planter 50 frø med sannsynlighet 0,8 for å spire kan vi bruke:
import numpy as np
tilfeldig_tall = np.random.binomial(50, 0.8)
Eksempel på simulering fra eksempeleksamen høst 2022
På en skole er det 323 jenter og 301 gutter.
er høyden på en tilfeldig valgt jente. er høyden på en tilfeldig valgt gutt. Anta at
og er normalfordelt med . Lag et program som du kan bruke til å simulere sannsynligheten for at en tilfeldig valgt elev er høyere enn 175 cm.
import random
n_x = 323
n_y = 301
mu_x = 168
mu_y = 180
s_x = 6
s_y = 8
grense = 175
antall_simuleringer = 10000
antall_gunstige = 0
for i in range(antall_simuleringer):
# Vi trekker en tilfeldig elev, men vi må finne ut om
# eleven er gutt eller jente.
# Det er 301 gutter. Hvis vi trekker et tilfeldig tall mellom
# 1 og 301+323=624 så kan vi si at dersom tallet er mindre enn
# eller lik 301, så er det en gutt.
if (random.randint(1, n_x + n_y) <= n_y):
# Her har vi altså trukket en gutt og vi trekker en tilfeldig gutt
# fra en normalfordeling
hoyde = random.gauss(mu_y, s_y)
else:
# ellers har vi trukket ei jente
hoyde = random.gauss(mu_x, s_x)
if (hoyde > grense):
antall_gunstige += 1
sannsynlighet = antall_gunstige/antall_simuleringer
print(f"Sannsynligheten for å trekke en tilfeldig elev over 175 cm er "
f"estimert til {sannsynlighet * 100:.1f} "
f"med {antall_simuleringer} simuleringer")
Eksempel på simulering fra eksamen høst 2023
Høyden X til en tilfeldig valgt jente på 24 måneder er tilnærmet normalfordelt med forventningsverdi
cm og standardavvik cm. Høyden Y til en tilfeldig valgt gutt på 24 måneder er tilnærmet normalfordelt med forventningsverdi
cm og standardavvik cm. Lag et program som du kan bruke til å anslå sannsynligheten for at høyden til et tilfeldig valgt barn på 24 måneder er mindre enn 84 cm. Gå ut ifra at det er like mange jenter som gutter i populasjonen.
import random
EX = 87
SDX = 3.3
EY = 88
SDY = 3.1
N = 100_000
antall_gunstige = 0
for i in range(N):
tilfeldig_tall = random.randint(1,2)
if tilfeldig_tall == 1:
# Vi har trukket en jente
hoyde = random.gauss(EX, SDX)
else:
# Vi har trukket en gutt
hoyde = random.gauss(EY, SDY)
if hoyde < 84:
antall_gunstige += 1
sannsynlighet = antall_gunstige / N
print(sannsynlighet)
Hypotesetesting
Vi bruker hypotesetester til å trekke slutninger om en hel populasjon basert på et utvalg eller stikkprøve.
I hypotesetester så bestemmer vi sannsynligheten for at observasjonene våre kan forekomme, gitt at en nullhypotese er sann.
Tabell: Begreper til hypotesetesting
| Begrep | Forklaring |
|---|---|
| Hypotesetesting | Gjøre et utvalg/stikkprøve av en populasjon og finne ut om vi kan forkaste en nullhypotese. |
| Nullhypotese ( |
Den gjeldende hypotesen eller det vi ønsker å motbevise. Vi antar at denne er sann i hypotesetesting. |
| Alternativ hypotese ( |
Den hypotesen vi ønsker å teste ("bevise") |
| Testobservator ( |
En stokastisk variabel med en valgt sannsynlighetsfordeling forutsatt at |
| Signifikansnivå ( |
Er som oftest 0,05. Det betyr at vi forkaster nullhypotesen i 5 % av tilfellene hvor vi ikke burde forkastet den (at vi gjør feil i 5 % av tilfellene). |
| Sannsynligheten for observasjonen, gitt at |
|
| Forkastningsmengde | De verdier av |
| Aksepteringsmengde | De verdier av |
| Venstresidig test | Tester om andelen er mindre enn nullhypotesen, altså |
| Høyresidig | Tester om andelen er større enn nullhypotesen, altså |
| Tosidig test | Tester om den egentlige verdien er ulik fra nullhypotesen |
- Sett opp nullhypotese og alternativ hypotese. Nullhypotesen er det vi ønsker å motbevise.
- Anta at nullhypotesen er sann og sett opp sannsynlighetsfordelingen for
- Regn ut
-verdien (sannsynligheten for å få observasjonene gitt at nullhypotesen er sann) - Sammenlign
-verdien med signifikansverdien . betyr at vi forkaster . Sannsynligheten for at observasjonene skal oppstå tilfeldig er mindre enn signifikansnivået. betyr at vi ikke forkaster . Sannsynligheten for at observasjonene skal oppstå tilfeldig er større enn signifikansnivået.
- Skriv konklusjon
Hypotesetesting av andeler
Vi undersøker om sannsynligheten
- Venstresidig test
. - Høyresidig test
- Dobbeltsidig test
- Vi velger
som testobservator og tar en stikkprøve der får verdien . - Vi regner ut
-verdien[4] - Ved venstresidig test så beregner vi
-verdien . - I en høyresidig test regner vi ut
-verdien . - I en dobbeltsidig test regner vi ut
-verdien .
- Ved venstresidig test så beregner vi
- Hvis
så forkaster vi
Hypotesetest av andel ved å bruke normalfordeling
Siden binomiske fordelinger kan være tilnærmet normalfordelte (se kapittel 6.4.2), så kan vi bruke normalfordelingen til å teste andeler når
I hypotesetesten bruker vi da en normalfordeling med
Hypotesetesting av gjennomsnitt
La
I hypotesetesten vår så bruker vi en normalfordeling med
Merk at
Python-lister begynner på indeks 0. Det vil si at for å hente ut det første elementet i ei liste som hetermin_listeså skriver vimin_liste[0]. For å hente du det fjerde elementet i lista skriver vimin_liste[3]. ↩︎Denne formelen tror jeg ikke du trenger å pugge til del 1 av eksamen. ↩︎
Monte Carlo er en bydel i Monaco som er kjent for sine mange kasinoer. Metoden kalles Monte Carlo siden den er basert på tilfeldigheter og sjansespill. ↩︎
-verdi og sannsynligheten i binomisk modell er ikke det samme. ↩︎